
Introduction
Many applications like smart manufacturing, surveillance and augmented reality require Artificial Intelligence to be implemented on the EDGE. Some of the challenges in implementing AI on the EDGE are –
- Achieving lowest possible latency
- Network pruning to improve performance without compromising on accuracy
- Flexible hardware that can keep pace with innovation
The Xilinx Edge AI platform is well suited for such applications as it is built on adaptable compute platform that retains the flexibility to change as per latest innovation (allowing only domain specific architectures to be updated) while delivering on low latency and end to end acceleration. The Xilinx Edge AI Platform provides comprehensive tools and models which utilize unique deep compression and hardware-accelerated Deep Learning technology. The Xilinx Edge platform delivers exceptional performance using pruning technology which is discussed in detail in Part 2 of this blog post.
Following are steps involved in implementing an EDGE AI solution for a specific application:
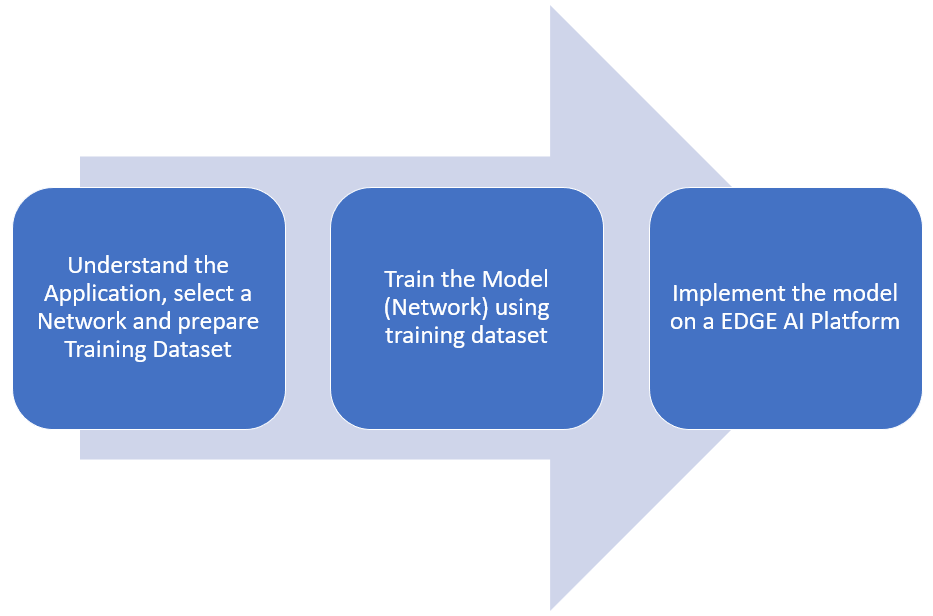
In this case study we will discuss the implementation of a classification model that we have developed for a retail use case using Xilinx Edge AI platform on a Zynq UltraScale+ Evaluation board (ZCU106).
Xilinx Edge AI Architecture
The Xilinx Edge AI platform provides comprehensive tools to implement Deep Learning on Zynq hardware.
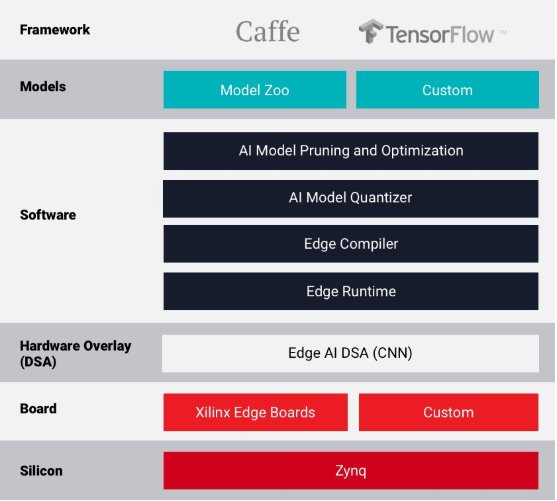
YantraVision has extensive capability in developing solutions using Deep Learning for applications in the Retail and Manufacturing industry. For the purpose of this case study we have implemented the classification model that we use in our Retail solution on a Zynq UltraScale+ Evaluation board using Xilinx Edge AI platform.
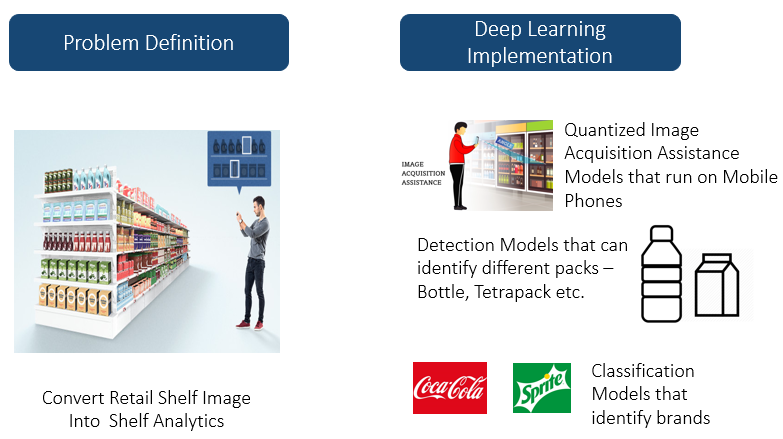
Evaluation Results for Retail Application
| CNN | Vgg16Net |
| Elapsed CPU time for the training (sec) | 3600 seconds |
| Parameters | 15,250,250 |
| Epochs | 60 |
| Dataset | fmnist |
| TF Output Node | dense_2/softmax |
| Training Accuracy | 0.91360 |
| Frozen graph top-1 accuracy | 0.8854 |
| Quantized graph top-1 accuracy | 0.8854 |
| Run time accuracy in board | 0.95 |
| Throughput(fps) in board | 54.8419 |
Conclusion
The Xilinx Edge AI platform is built on adaptable compute platform that retains the flexibility to change as per latest innovation (allowing only domain specific architectures to be updated) while delivering on low latency and end to end acceleration. The Xilinx Deep Learning Processor Unit (DPU) is part of the EDGE AI stack and is a programmable engine dedicated for convolutional neural network (CNN). The DPU IP can be integrated as a block in the programmable logic (PL) of the selected Zynq-7000 SoC and Zynq UltraScale™+ MPSoC devices with direct connections to the processing system (PS).
Yantravision has extensive capability in building and training our own neural network models. We also have the capability to implement on Deep Learning using Xilinx Edge AI.
For details regarding building a Deep Learning solution on Xilinx from scratch write to us at sales@yantravision.com