
Recap of the Business Case
We develop High Speed Embedded Vision modules for use cases in the Textile Industries. These high-speed modules are built using our proprietary Image Signal Processors (ISP) that run on Zynq platform. One of the challenges that we face is to differentiate colour and texture of objects from the background. We use deep learning for such use cases and as they are hard real time requirements, we implement them on embedded FPGA processors. In this context we continuously explore methods (like DPU and Pynq – BNN) to implement deep learning on embedded FPGA. This blog post is about our experience in implementing such applications using Pynq – BNN.
Previous Posts in the same Blog Series –
Part 1 – Why Binary Neural Networks?
Part 2 – Why PYNQ framework?
Implementing Pynq – BNN
Step 1: Training our own network
Dataset Preparation:
Depending on the requirement of the application either Monochrome or RGB dataset is prepared in the appropriate format. In our case we have prepared RGB dataset from Fabric texture samples in cifar10 format. This dataset will be used to train a convolution network.
Prepare Training Environment:
GPU is well suited for training the network. Before starting the training, the environment preparation includes installing below libraries in conda environment of GPU –
- Theano
- Lasagne
- Pylearn2
- Pillow
Training:
In general, monochrome datasets are trained using LFC network and RGB datasets are trained using CNV network. The Pynq project (Jupyter notebook) provides scripts that need to be customized as per the dataset and the network being trained.
In our case we trained the CNV network and the output of the training was a npz file that will have the weights and the parameters to find thresholds.
We trained the cnvW2A2 version of the network and below are the training results –
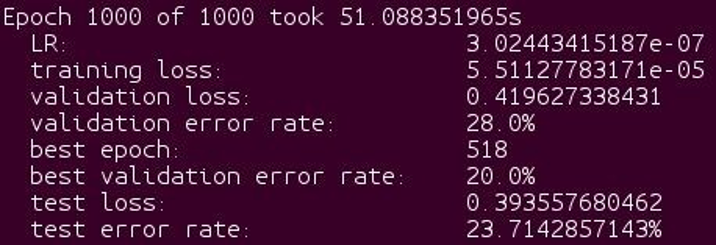
Step 2: Binarize the network
In this process, the .npz format is converted to Binary weight. In order to load them into the Pynq-BNN overlay, the real floating point values of weight file are converted into binary values and packed into .bin files.
Currently LFC network supports 1-bit weights and 1 or 2 bit activations while CNV network supports 1 or 2 bit weights and 1 or 2 bit activations. The floating point weights and batch normalization parameters are binarized using the scripts provided in the Pynq – BNN project.
Things to remember:
- If some changes have been made to the memory device controller, the hardware overlay has to be rebuilt.
- Before executing the hardware generation flow the h file generated during the weight generation process has to be moved to the appropriate hw folder.

The above binarized parameters can also be verified using csim feature in Vivado HLS tool.
Step 3: Hardware / Software Synthesis
The Pynq project can be used to generate bitstream and tcl files from the binary weights file. Some of the options available for different networks, hardware platforms and synthesis mode –
- Network can be ‘cnvW1A1’, ‘cnvW1A2’, ‘cnvW2A2’ or ‘lfcW1A1’, ‘lfcW1A2’;
- Platform can be ‘pynqZ1-Z2’ or ‘ultra96’;
- Mode can be ‘h’ to launch Vivado HLS synthesis, ‘b’ to launch the Vivado project (needs HLS synthesis results) or ‘a’ to launch both.
In our project the network design was synthesized for implementation via Vivado Design Studio and the utilization estimation are as follows –
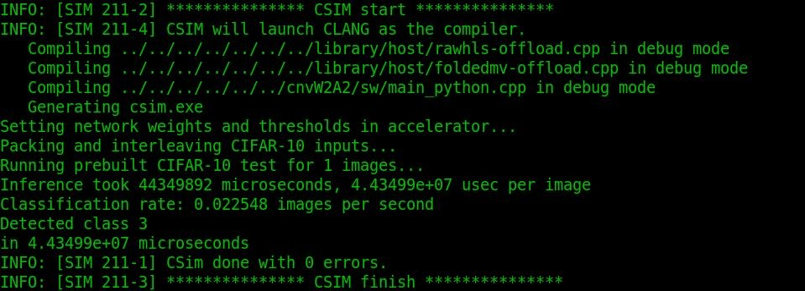
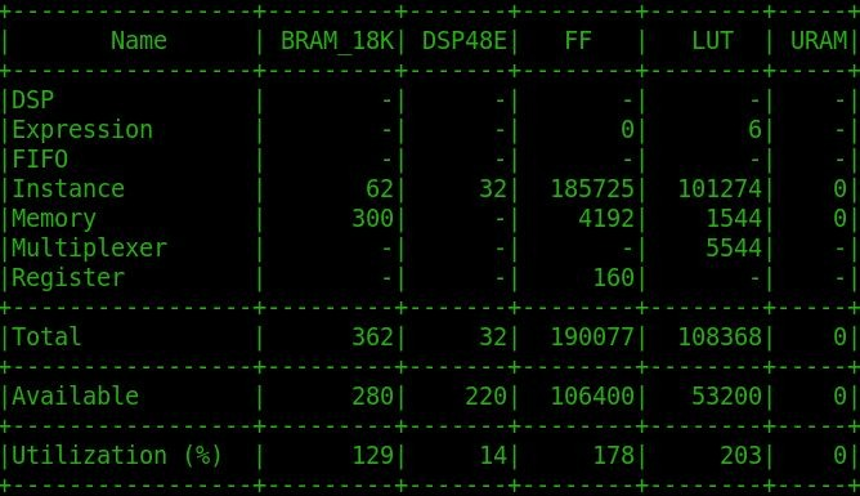
Step 4: Inference Validation
Based on the hardware platform on which the design has to be implemented the relevant libraries have to be installed and the bitstream and tcl files need to be installed.
The Python notebook can be used to instantiate a classifier
(Eg.: bnn.CnvClassifier(bnn.NETWORK_CNVW1A1,’cifar10′,bnn.RUNTIME_HW) that can be used for classifying test images that is used for validation.
In our case the design was validated on an Arty Z7 board for over 1000 images with an error rate < 10%.

Conclusion
Pynq – BNN is an effective method to implement EDGE AI use cases on Embedded FPGA processors. Since it is implemented using Pynq it makes it easy for software developers with limited knowledge of FPGA to take advantage of the acceleration advantages on the EDGE.